

In our previous articles, we explored how generative AI is moving software from deterministic systems to probabilistic ones, where variability is built in by design. We then looked at what this means for designers: shifting from precise user flows to adaptive systems that embrace uncertainty.
In this third part, we turn to development. How can teams build reliable, auditable, and trustworthy systems when the technology at the centre of them is inherently variable? I spoke with Diego Ramirez, one of our Software Developers, about the practical realities of building around non-deterministic systems.
Diego, what’s different for developers when building applications with generative AI?
For developers, it means moving from controlling every variable to managing boundaries. Traditional software is about precision. Generative systems don’t work that way. The job now is to define constraints, build guardrails, and create space for controlled flexibility. It’s less about enforcing one right answer and more about ensuring every possible answer stays within acceptable limits.
It takes a different mindset, since most developers are trained to build for precision and repeatability. But it also changes how we build. Instead of hardcoding decisions, we start shaping conditions: what the system should always do, what it must never do, and where it has freedom to adapt. You’re still designing for consistency, not necessarily identical results.
When teams start building with that mindset, where should they begin?
Always start with the problem, not the technology. Before touching any models or APIs, define the use case and the outcomes you want. Are you summarizing long reports, explaining complex policies or helping users navigate services? Each of those requires different models, configurations and controls.
Once you know the purpose, define boundaries. Decide what tone and style the system should maintain, what behaviours are acceptable and which ones are not. For public-facing systems, that might mean building a whitelist of approved topics or a blacklist to avoid sensitive or speculative areas. These decisions form the foundation for your guardrails.
Then set metrics. Without them, tuning a non-deterministic system becomes guesswork. Accuracy, clarity, tone, latency and cost are all measurable. The goal is to channel AI’s flexibility into consistent and reliable outcomes.
So once the foundation is there, how do you control that variability?
We manage it in layers. Each layer tackles variability at a different stage–before the model runs, while it generates and after it produces an answer.
Input Stage: Validation and scope
At the input stage, validation and scope checks stop irrelevant or unsafe requests before they reach the model.
Prompt Stage: Instructions and structure
At the prompt level, we use clear instructions and ask for structured outputs like JSON or tables to make results easier to test and reuse. Sometimes we add a few examples to help anchor the model’s behaviour. This is called few-shot prompting. And critically, we version our prompts so we can track which version produced which outputs, making it possible to improve them over time.
Retrieval Stage: Context and grounding
Retrieval plays a big part too. Many systems use retrieval-augmented generation, or RAG, which lets the model pull information from trusted sources before it responds. The system first searches your document store for relevant content, then provides that context to the model as grounding for its response. The tighter and more relevant that retrieval pipeline is, the more consistent your results will be.
Output Stage: Filtering and enforcement
And after generation, we use output filters to enforce structure, formatting and content rules. Those filters catch things like missing disclaimers or disallowed topics. Altogether, these layers form a control system that channels variability into something useful instead of chaotic.
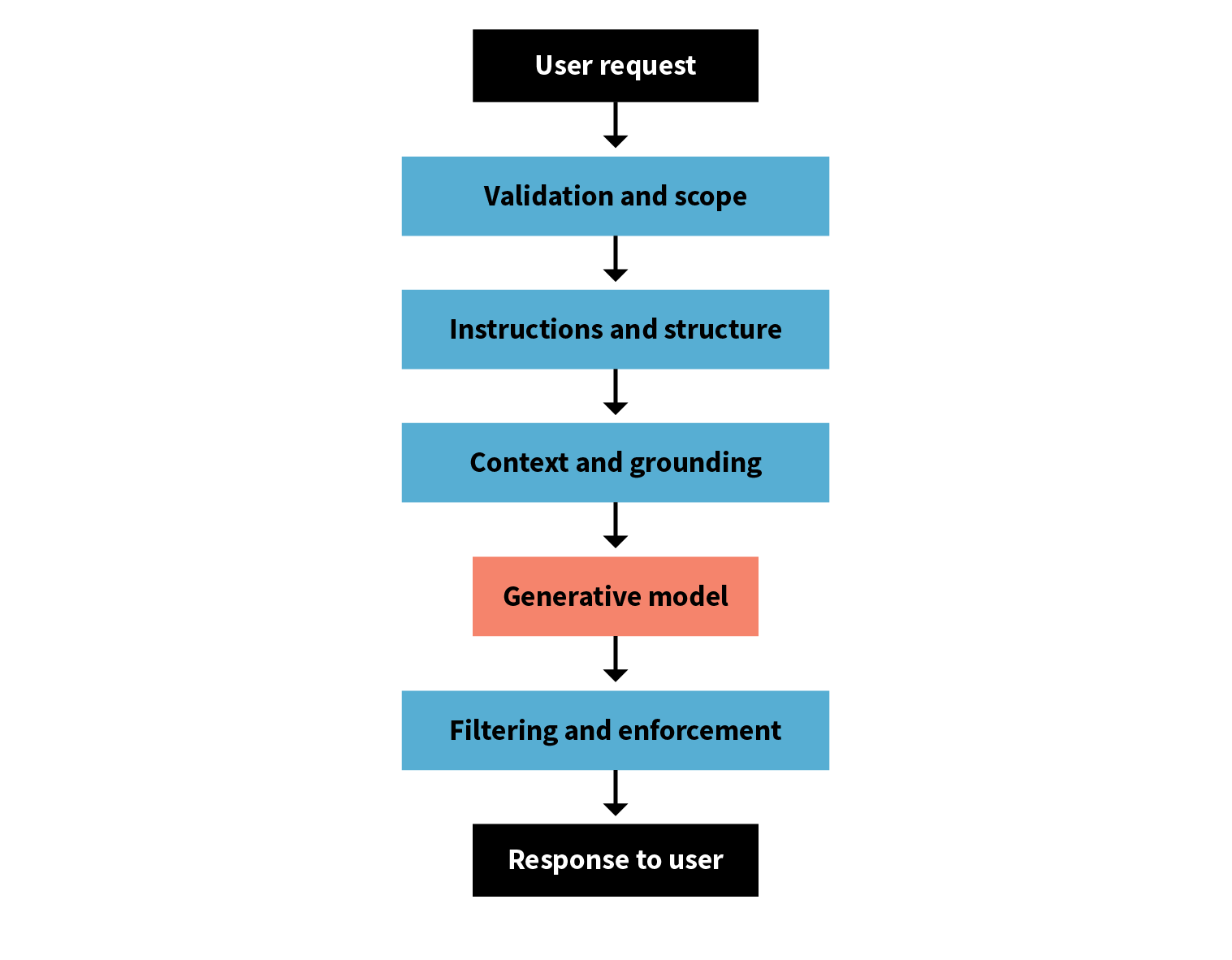
That layering makes sense. But how do you keep uncertainty from spreading into other parts of the system?
Through isolation. We keep deterministic and non-deterministic components separate so one can’t compromise the other.
All the critical parts like business logic, data validation and compliance checks stay deterministic and predictable. That’s where consistency matters most. The AI-driven parts, like summarization or generating explanations, live in their own contained modules. Between them sits a control layer that manages input validation, logging and fallback logic.
Clear separation also supports accountability. When deterministic and AI-driven components are distinct, it’s easier to audit decisions and explain system behaviour. This is crucial in regulated environments.
If something goes wrong in that non-deterministic layer, the system can recover gracefully. Maybe it returns a safe default, retries with stricter parameters or hands the request to a human reviewer. The key is that the AI is contained; it can evolve without risking the integrity of the rest of the system.
Can you give an example of what that looks like in real life?
Take a service that summarizes policy documents for the public.
First, input validation checks that the file is the right format and the user is authorized. Then, retrieval logic pulls relevant sections from the policy database and applies business rules to determine what can be shared. The generative layer uses that context to produce a plain-language summary. Finally, output validation ensures the summary meets the expected structure, includes disclaimers and avoids restricted topics.
If any of those steps fail, the system falls back to a safe message or routes it for review. The generative component might only account for a small slice of the pipeline, but that small slice adds huge value by making complex information accessible.
Even with all these controls, some variability will always remain. The goal isn’t to eliminate it but to make it predictable and safe.
With all these layers and controls in place, how do you decide which models to use?
It’s always a trade-off. Some models are faster or cheaper, while others reason more deeply or perform better in specific domains. You don’t need the most capable model for every use case. A smaller model extracting keywords might cost pennies per thousand requests, while a large model doing complex reasoning might cost dollars.
A good pattern is to match the model to the complexity of the task. Simple requests like formatting or keyword extraction can go to smaller models. Larger, more capable ones handle the nuanced reasoning. Routing requests this way balances cost, speed and quality and lets you scale responsibility.
That makes sense. So what happens after you launch?
Well, the work doesn’t stop there. Generative systems don’t reach a “finished” state; they evolve. That’s where feedback loops come in.
You collect signals from users (e.g., thumbs up or down) and link that feedback to the context that produced it. When you know which prompt, model and parameters were involved, you can identify patterns and make targeted improvements. If users consistently thumbs-down a certain type of response, you can adjust the prompt, refine the retrieval or add output filtering for that case.
Alongside user feedback, teams log prompts, parameters and model versions to understand why outputs change over time. That visibility turns experimentation into a disciplined process. Over time, that data shows you where to refine prompts, adjust retrieval strategies or update models.
The teams that succeed are the ones that treat feedback as a continuous tuning mechanism, not a one-off QA step.
For teams just starting out, what advice would you give?
Start small. Pick one contained, low-risk use case where variability is acceptable and use it to learn. Define success metrics before you start building. Keep your architecture layered so you can adjust the AI components without touching the core logic.
And remember that stability will come through iteration, not control. Treat your generative systems like a living product that evolves through experience. Building around non-deterministic systems isn’t about removing uncertainty, it’s about engineering for it.
Have you read the first two articles in our series yet? Software for the generative age: From precision to probability discusses how generative AI is moving software from deterministic systems to non-deterministic ones. Software for the generative age: Designing for non-determinism explores how to shift from predictable design to systems that embrace uncertainty.